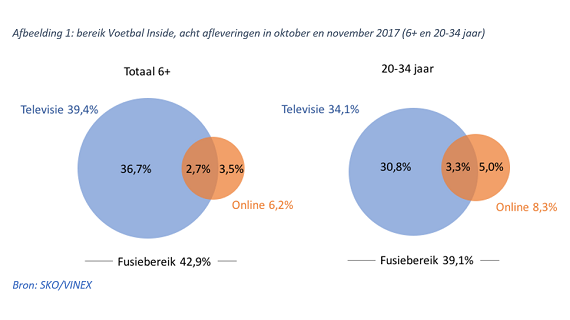
In deze column legt Karen Nelson-Field uit wat de juiste onderzoeksaanpak is om van losse cases naar breed inzetbare kennis te gaan
Professor Karen Nelson-Field, oprichter van Amplified Intelligence, levert in de vorm van een tweemaandelijkse column een vaste bijdrage aan reclame expertisecentrum Warc. In haar tweede column beschrijft ze de kwalitatieve eisen die gesteld moeten worden aan de datastroom om in de toekomst het succes van de aandachtseconomie te garanderen. Volgens haar hebben we een combinatie nodig van observatie van persoonlijk menselijk gedrag en van grootschalige impressiedata. Ze vat dit alles samen in een overzichtelijke figuur die de negen achtereenvolgende stappen van deze datastroom weergeeft.
Aandachtdata onder de microscoop
De meest geavanceerde bedrijfstakken staan open voor vernieuwingen. De online media-industrie verdient daarbinnen een prominente plaats. Door de veranderingen qua aandachtmetingen de afgelopen jaren, geleidt door pionierende merken en mediabureaus, zijn voorheen opkomende aandachtconcepten inmiddels uitgegroeid tot vaststaande feiten. De brede kloof tussen op impressiedata gebaseerde metingen en daadwerkelijk gemeten menselijke aandacht is nu wereldwijd geaccepteerd. Met de daaraan gerelateerde problemen voor adverteerders die inzicht willen hebben in de relatieve waarde van hun reclame-investeringen voor verschillende media. Het is nu erkend dat aandachtdata deze kloof qua relatieve waarde in kaart kan brengen en kan overbruggen voor mediaplanning, media-inkoop en voor verificatieprocessen.
De diverse spelers in het ecosysteem kunnen terecht trots zijn op zichzelf dat zij een positie hebben bereikt waar de uitdagingen bij campagnebeoordelingen en de oplossingen daarvoor vanuit aandachtmetingen bekend zijn. Beter begrip in hoe de toekomst voor aandachtmetingen eruitziet is nog wel noodzakelijk.
Om het speelveld te beschrijven; aandachtdata vallen grofweg in twee categorieën; menselijke en niet-menselijke data. Een gemakkelijke manier om het verschil hiertussen uit te leggen is om de eerste te zien als ‘naar buiten gerichte’ data, waarbij op persoonsniveau via oogbeweging registratie of gezichtsherkenning menselijk gedrag wordt geobserveerd, en de tweede als ‘naar binnen gerichte’ data. Daarbij worden via pixels op impressieniveau data verzamelt met als doelstelling aannames te kunnen doen over menselijk gedrag.
Elke dataset kent zijn eigen beperkingen. Het continu en op grote schaal filmen van mensen op het niveau van onderzoek panels heeft ethische implicaties: Niemand wil een currency die in principe bestaat uit grootschalig toezicht. Pixel data daarentegen zijn weliswaar schaalbaar maar hun capaciteit om menselijk gedrag betrouwbaar te voorspellen is uiterst beperkt (zie de laatste column voor Warc).
We hebben een combinatie van beiden nodig, een samensmelting van data die persoonlijk menselijk gedrag koppelt aan grootschalige impressiedata.
Jonathan Wells, een datawetenschap veteraan die voor Nielsen werkt, heeft zich hier recent in een paper over uitgesproken: ‘ … een lucratieve databron zoals ACR (automatic content behavior) is op zichzelf niet voldoende om bereik te meten, simpelweg omdat het belangrijkste aspect van bereik onderzoek ontbreekt: mensen. De beste manier om het potentieel van ACR-data te ontketenen is om ze te kalibreren met data van menselijk gedrag op persoonsniveau. Datawetenschappers noemen dit ‘ground truth’.
Het kritieke belang van ‘ground truthing’
In zelflerende algorithmes is ‘ground truth’ de term die aangeeft dat er een ‘bewijsbaar’ of ‘waar’ antwoord is op een bepaalde vraag. Dit type data wordt verzameld door intensieve en directe observatie van echte kenmerken en eigenschappen in context. Dat in tegenstelling tot gemodelleerde data die een aanname doet over het echte antwoord. Hoe fundamenteler en accurater the ground truth data zijn, des te groter de voorspellende waarde van de algoritmes is.
In de context van de aandachtseconomie zijn ground truth data zoals hierboven beschreven: via oogbeweging registratie of gezichtsherkenning menselijk gedrag real time observeren op persoonsniveau. Het vertelt je precies hoeveel tijd, met welke focus een persoon besteedt aan reclame. Aan de andere kant zijn er gemodelleerde aandachtdata, data die op impressieniveau worden verzameld door tracking via pixels om informatie te verzamelen over scroll-snelheid, time-in-view, reclame pixel load en het deel van het scherm dat door de reclame wordt bedekt. Het vertelt ons hoe de reclame is ge-upload tijdens de kijksessie en hoe deze werd weergegeven op het scherm. De hoeveelheid aandacht besteedt door de kijker is zuiver en alleen gebaseerd op de kwaliteit en kwantiteit van de ground truth data waarop de voorspelling is gebaseerd.
De ene bron is hoog van kwaliteit maar laag in kwantiteit, de ander is laag in kwaliteit maar hoog in kwantiteit (miljarden data punten).
De onderstaande figuur beschrijft de fundamentele kwaliteit van de datastroom die benodigd is voor het succes in de toekomst van de data-economie binnen reclame. Centraal staat een duidelijke maar diepgaande data interface die zowel ground truth data als afgeleide data verbindt om een duidelijke omschrijving te leveren van aandachtmetingen binnen een functioneel en toekomstbestendig ecosysteem.

De optimale data-flow verloopt als volgt:
- Ground truth database: De enige ground truth data die het fundament kan vormen van betrouwbare aandacht meettechnieken en modellen is afkomstig van menselijke panels. Specifiek moeten oogbewegingen, gezichtsherkenning plus pixel traffic data op impressieniveau worden gemeten bij een en dezelfde persoon gedurende de hele tijd dat reclames zichtbaar zijn. Door de impressie data en oogbeweging data bij dezelfde persoon te meten kunnen we een solide link bouwen naar impressieniveau data.
- Impression Level database: Deze data, door middel van tracking via pixels verzameld, geven een indicatie voor menselijke aandacht (bijvoorbeeld snelheid van het scrollen) maar vanwege het ontbreken van menselijke data is dit op zichzelf onvoldoende om menselijke aandacht te voorspellen. Dat komt vanwege de gevarieerde en complexe combinatie van indicatoren die het kijken naar de verschillende reclame formats voorspellen. Met andere woorden, de complexiteit van menselijk gedrag kan niet alleen op basis van deze data worden voorspeld.
- Enriched database: De beide bovenstaande databases worden gecombineerd in een verrijkte database waarin de learnings uit de ground truth database worden gekoppeld aan de impression level data om betrouwbare aandachtvoorspellingen te kunnen doen op een multi-miljard reclame impressie schaal.
- Attention algoritmes: Verschillende modellen, gericht op zowel aandachtseconden als aandachtfocus, ondersteunen de verschillende applicaties van aandachtmetingen binnen de media. Tijd is het aantal seconden dat er aandacht wordt besteed, focus is de mate van concentratie gedurende die seconden (veel/weinig switchen van aandacht, blijvende/wisselende focus). Modellen die tweedimensionale aandacht factoren combineren kunnen betrouwbaar effecten voorspellen waardoor adverteerders aandachtdata praktisch kunnen toepassen.
- Attention models for mediaplanning: Modellen die worden gebouwd voor mediaplanning tools passen wegingsfactoren toe om te optimaliseren op aandacht om de efficiëntie van het mediaplan te vergroten. Het optimale aandachtniveau wisselt afhankelijk van de campagnedoelstellingen.
- Attention Models for Media Trading:Op maat gebouwde probabilistische modellen voor media-inkoop zorgen dat adverteerders kunnen bieden en kopen op basis van aandacht scores als een juiste combinatie en gewicht van aandacht-indicatoren aanwezig zijn voor een transactie.
- Attention Models for Media Verification: In-flight campagne optimalisatie om de aandacht en campagne effectiviteit van een impressie te meten nadat een impressie is uitgeleverd.
- Feedback Loop between Applications: Feedback vormt geen onderdeel binnen de datastroom als machine-leer-proces maar het is wel belangrijk om in het oog te houden hoe dat elk onderdeel van de datastroom de ander beïnvloedt. Wanneer adverteerders of mediabureaus de stappen van de datastroom opvolgen zal elke stap de er opvolgende stap verbeteren. Bijvoorbeeld zorgt geoptimaliseerde mediaplanning voor een verbetering van de inkoopbeslissingen. Geoptimaliseerde inkoopbeslissingen zorgen voor betere bewijsnummering/verificatie en betere bewijsnummering zorgt voor beter mediamix scenarioplanning.
- Ongoing Collection and Tracking: Alle data moeten regelmatig worden geüpdate voor continue verbetering van het machineleermodel. Alle nieuwe verificatie data moeten worden ingevoerd in de impressiedatadatabase die vervolgens weer de verrijkte database voedt. Alle menselijke data dienen regelmatig opnieuw geüpdate te worden omdat als de functionaliteit van een platform verandert ook de wijze waarop mensen hiermee omgaan verandert. Zonder nieuwe menselijke gebruiksdata zal de voorspellingswaarde van het aandachtmodel achteruitgaan.
Menigeen begrijpt de uitdrukking ‘Het geheel is groter dan de som der delen’. Dit is hier ook geldig. De op pixelregistratie gebaseerde impressiedata op zichzelf vertellen ons niet of dat een mens er ook met aandacht naar heeft gekeken. En menselijke data zijn moeilijk op een grote schaal te verzamelen. Het ene is informatie over menselijk gedrag op kleine schaal het ander geeft ons een onduidelijker beeld van menselijk gedrag maar laat wel het grote geheel zien. De combinatie van beiden levert zowel duidelijkheid als schaal, gecombineerd veranderen zij het mediametingenlandschap.
Toekomstbestendigheid is essentieel
Wat de aandachtindustrie tot en met nu heeft laten zien vormt nog maar het topje van de ijsberg. We hebben nu bewijzen op basis van losse cases die het succes laten zien van aandachtmetingen. Maar de reclame industrie moet scherpe, samenhangende inzichten krijgen van hoeveel betrokkenheid èlke reclame krijgt van de consument en een gevalideerde blauwdruk voor de echte integratie van aandachtdata in het brede mediametingen ecosysteem.
Deze datastroomanalyse verplaatst de focus van losse aandachtconcepten naar samenhangende aandachtwetenschap. Die verplaatste focus is nodig is voor de succesvolle toepassing van aandachtdata voor mediaplanning, -inkoop en -verificatiesystemen.
Waarom is dit belangrijk? Als we niet streng zijn en we blijven werken met een onduidelijk en op zichzelf staande routekaart dan lopen we het risico dat simplistische aandachtmetingmodellen meer kwaad doen dan goed. We komen uit een situatie waar goed genoeg, goed genoeg was en de reclame industrie en de adverteerders die voor dit alles betalen zijn hiervan nu het slachtoffer, vanwege de miljarden verspild geld aan reclames die niet eens gezien worden door mensen.
Deze tekst is een vertaling door Screenforce van de tweede column van Karen Nelson Field voor Warc.